У java есть реализация списка пропуска. Еще раз про skiplist… С какого уровня начинать искать? Определение L(n)
Списки с пропусками - это структура данных, которая может применяться вместо сбалансированных деревьев. Благодаря тому, что алгоритм балансировки вероятностный, а не строгий, вставка и удаление элемента в списках с пропусками реализуется намного проще и значительно быстрее, чем в сбалансированных деревьях.
Списки с пропусками - это вероятностная альтернатива сбалансированным деревьям. Они балансируются с использованием генератора случайных чисел. Несмотря на то, что у списков с пропусками плохая производительность в худшем случае, не существует такой последовательности операций, при которой бы это происходило постоянно (примерно как в алгоритме быстрой сортировки со случайным выбором опорного элемента). Очень маловероятно, что эта структура данных значительно разбалансируется (например, для словаря размером более 250 элементов вероятность того, что поиск займёт в три раза больше ожидаемого времени, меньше одной миллионной).
Балансировать структуру данных вероятностно проще, чем явно обеспечивать баланс. Для многих задач списки пропуска это более естественное представление данных по сравнению с деревьями. Алгоритмы получаются более простыми для реализации и, на практике, более быстрыми по сравнению со сбалансированными деревьями. Кроме того, списки с пропусками очень эффективно используют память. Они могут быть реализованы так, чтобы на один элемент приходился в среднем примерно 1.33 указатель (или даже меньше) и не требуют хранения для каждого элемента дополнительной информации о балансе или приоритете.
Для поиска элемента в связном списке мы должны просмотреть каждый его узел:
Если список хранится отсортированным и каждый второй его узел дополнительно содержит указатель на два узла вперед, нам нужно просмотреть не более, чем ⌈n
/2⌉ + 1 узлов(где n
- длина списка):
Аналогично, если теперь каждый четвёртый узел содержит указатель на четыре узла вперёд, то потребуется просмотреть не более чем ⌈n
/4⌉ + 2 узла:
Если каждый 2 i
i
узлов вперёд, то количество узлов, которые необходимо просмотреть, сократится до ⌈log 2 n
⌉, а общее количество указателей в структуре лишь удвоится:
Такая структура данных может использоваться для быстрого поиска, но вставка и удаление узлов будут медленными.
Назовём узел, содержащий k указателей на впередистоящие элементы, узлом уровня k
. Если каждый 2 i
-ый узел содержит указатель на 2 i
узлов вперёд, то уровни распределены так: 50% узлов - уровня 1, 25% - уровня 2, 12.5% - уровня 3 и т.д. Но что произойдёт, если уровни узлов будут выбираться случайно, в тех же самых пропорциях? Например, так:
Указатель номер i каждого узла будет ссылаться на следующий узел уровня i или больше, а не на ровно 2 i -1 узлов вперёд, как было до этого. Вставки и удаления потребуют только локальных изменений; уровень узла, выбранный случайно при его вставке, никогда не будет меняться. При неудачном назначении уровней производительность может оказаться низкой, но мы покажем, что такие ситуации редки. Из-за того, что эти структуры данных представляют из себя связные списки с дополнительными указателями для пропуска промежуточных узлов, я называю их списками с пропусками .
Операции
Опишем алгоритмы для поиска, вставки и удаления элементов в словаре, реализованном на списках с пропусками. Операция поиска возвращает значение для заданного ключа или сигнализирует о том, что ключ не найден. Операция вставки связывает ключ с новым значением (и создаёт ключ, если его не было до этого). Операция удаления удаляет ключ. Также в эту структуру данных можно легко добавить дополнительные операции, такие как «поиск минимального ключа» или «нахождение следующего ключа».Каждый элемент списка представляет из себя узел, уровень которого был выбран случайно при его создании, причём независимо от числа элементов, которые уже находились там. Узел уровня i содержит i указателей на различные элементы впереди, проиндексированные от 1 до i . Мы можем не хранить уровень узла в самом узле. Количество уровней ограничено заранее выбранной константой MaxLevel . Назовём уровнем списка максимальный уровень узла в этом списке (если список пуст, то уровень равен 1). Заголовок списка (на картинках он слева) содержит указатели на уровни с 1 по MaxLevel . Если элементов такого уровня ещё нет, то значение указателя - специальный элемент NIL.
Инициализация
Создадим элемент NIL, ключ которого больше любого ключа, который может когда-либо появиться в списке. Элемент NIL будет завершать все списки с пропусками. Уровень списка равен 1, а все указатели из заголовка ссылаются на NIL.Поиск элемента
Начиная с указателя наивысшего уровня, двигаемся вперед по указателям до тех пор, пока они ссылаются на элемент, не превосходящий искомый. Затем спускаемся на один уровень ниже и снова двигаемся по тому же правилу. Если мы достигли уровня 1 и не можем идти дальше, то мы находимся как раз перед элементом, который ищем (если он там есть).Search
(list, searchKey)
x:= list→header
# инвариант цикла: x→key < searchKey
for
i:= list→level downto
1 do
while
x→forward[i]→key < searchKey do
x:= x→forward[i]
# x→key < searchKey ≤ x→forward→key
x:= x→forward
if
x→key = searchKey then
return
x→value
else
return
failure
Вставка и удаление элемента
Для вставки или удаления узла применяем алгоритм поиска для нахождения всех элементов перед вставляемым (или удаляемым), затем обновляем соответствующие указатели:
В данном примере мы вставили элемент уровня 2.
Insert
(list, searchKey, newValue)
local
update
x:= list→header
for
i:= list→level downto
1 do
while
x→forward[i]→key < searchKey do
x:= x→forward[i]
# x→key < searchKey ≤ x→forward[i]→key
update[i] := x
x:= x→forward
if
x→key = searchKey then
x→value:= newValue
else
lvl:= randomLevel()
if
lvl > list→level then
for
i:= list→level + 1 to
lvl do
update[i] := list→header
list→level:= lvl
x:= makeNode(lvl, searchKey, value)
for
i:= 1 to
level do
x→forward[i] := update[i]→forward[i]
update[i]→forward[i] := x
Delete
(list, searchKey)
local
update
x:= list→header
for
i:= list→level downto
1 do
while
x→forward[i]→key < searchKey do
x:= x→forward[i]
update[i] := x
x:= x→forward
if
x→key = searchKey then
for
i:= 1 to
list→level do
if
update[i]→forward[i] ≠ x then
break
update[i]→forward[i] := x→forward[i]
free(x)
while
list→level > 1 and
list→header→forward = NIL do
list→level:= list→level – 1
Для запоминания элементов перед вставляемым(или удаляемым) используется массив update . Элемент update[i] - это указатель на самый правый узел, уровня i или выше, из числа находящихся слева от места обновления.
Если случайно выбранный уровень вставляемого узла оказался больше, чем уровень всего списка (т.е. если узлов с таким уровнем ещё не было), увеличиваем уровень списка и инициализируем соответствующие элементы массива update указателями на заголовок. После каждого удаления проверяем, удалили ли мы узел с максимальным уровнем и, если это так, уменьшаем уровень списка.
Генерация номера уровня
Ранее мы приводили распределение уровней узлов в случае, когда половина узлов, содержащих указатель уровня i , также содержали указатель на узел уровня i +1. Чтобы избавиться от магической константы 1/2, обозначим за p долю узлов уровня i , содержащих указатель на узлы уровня i +i. Номер уровня для новой вершины генерируется случайно по следующему алгоритму:randomLevel
()
lvl:= 1
# random() возвращает случайное число в полуинтервале , length: " + length);
}
}
Вы можете использовать приведенное ниже код, чтобы сделать свой собственный базовый скипист :
1) Сделайте start и конец до represent start and end of skip list .
2) Add the nodes и assign pointers до следующего based on
If(node is even) then ,assign a fast lane pointer with next pointer else assign only pointer to next node
Java-код для базового списка пропуска (вы можете добавить дополнительные функции):
Public class MyClass { public static void main(String args) { Skiplist skiplist=new Skiplist(); Node n1=new Node(); Node n2=new Node(); Node n3=new Node(); Node n4=new Node(); Node n5=new Node(); Node n6=new Node(); n1.setData(1); n2.setData(2); n3.setData(3); n4.setData(4); n5.setData(5); n6.setData(6); skiplist.insert(n1); skiplist.insert(n2); skiplist.insert(n3); skiplist.insert(n4); skiplist.insert(n5); skiplist.insert(n6); /*print all nodes*/ skiplist.display(); System.out.println(); /* print only fast lane node*/ skiplist.displayFast(); } } class Node{ private int data; private Node one_next; //contain pointer to next node private Node two_next; //pointer to node after the very next node public int getData() { return data; } public void setData(int data) { this.data = data; } public Node getOne_next() { return one_next; } public void setOne_next(Node one_next) { this.one_next = one_next; } public Node getTwo_next() { return two_next; } public void setTwo_next(Node two_next) { this.two_next = two_next; } } class Skiplist{ Node start; //start pointer to skip list Node head; Node temp_next; //pointer to store last used fast lane node Node end; //end of skip list int length; public Skiplist(){ start=new Node(); end=new Node(); length=0; temp_next=start; } public void insert(Node node){ /*if skip list is empty */ if(length==0){ start.setOne_next(node); node.setOne_next(end); temp_next.setTwo_next(end); head=start; length++; } else{ length++; Node temp=start.getOne_next(); Node prev=start; while(temp != end){ prev=temp; temp=temp.getOne_next(); } /*add a fast lane pointer for even no of nodes*/ if(length%2==0){ prev.setOne_next(node); node.setOne_next(end); temp_next.setTwo_next(node); temp_next=node; node.setTwo_next(end); } /*odd no of node will not contain fast lane pointer*/ else{ prev.setOne_next(node); node.setOne_next(end); } } } public void display(){ System.out.println("--Simple Traversal--"); Node temp=start.getOne_next(); while(temp != end){ System.out.print(temp.getData()+"=>"); temp=temp.getOne_next(); } } public void displayFast(){ System.out.println("--Fast Lane Traversal--"); Node temp=start.getTwo_next(); while(temp !=end){ System.out.print(temp.getData()+"==>"); temp=temp.getTwo_next(); } } }
Вывод:
Простой обход -
1 = > 2 = > 3 = > 4 = > 5 = > 6 = >
Быстрая перемотка дорожки -
2 == > 4 == > 6 == >
Когда вы создаете ConcurrentSkipListSet , вы передаете компаратор в конструктор.
New ConcurrentSkipListSet<>(new ExampleComparator());
public class ExampleComparator implements Comparator
Вы можете создать компаратор, который сделает ваш SkipListSet вести себя как обычный список.
Я не утверждаю, что это моя собственная реализация. Я просто не могу вспомнить, где я его нашел. Если вы знаете, дайте мне знать, и я обновлю. Это работает для меня хорошо:
Public class SkipList
Исправлена ошибка в реализации, предоставляемой @PoweredByRice. Он выбросил NPE для случаев, когда удаленный node был первым node. Другие обновления включают переименованные имена переменных и обратную печать порядка списка пропусков.
Import java.util.Random;
interface SkippableList
Интересной разновидностью структуры данных эффективной реализации АТД «упорядоченный словарь» является skip^cnucoK (skip list). Эта структура данных организует объекты в произвольном порядке таким
образом, что поиск и обновление в среднем выполняются за 0(log п) времени, где п - количество объектов словаря. Интересно, что понятие усредненной временной сложности, используемое здесь, не зависит от возможного распределения ключей при вводе. Наоборот, оно продиктовано использованием генераторов случайных чисел в реализации процесса ввода, чтрбы облегчить процесс принятия решения о месте вставки нового объекта. Время выполнения в этом случае будет равно среднему значению времени выполнения ввода любых случайных чисел, используемых в качестве входных объектов.
Методы генерации случайных чисел встраиваются в большинство современных компьютеров, поскольку они широко применяются в компьютерных играх, криптографии и компьютерных симуляторах. Некоторые методы, называемые генераторами псевдослучайных чисел (pseudorandom number generators), генерируют псевдослучайно числа по некоторому закону, начиная с так называемого начального числа (seed). Другие методы используют аппаратные средства для извлечения «действительно» случайных чисел. В любом случае компьютер имеет числа, отвечающие требованиям, предъявляемым к случайным числам в приводимом анализе.
Основным преимуществом использования случайных чисел в струк- > туре данных и при создании алгоритма является простота и надежность результативных структур и методов. Таким образом можно-создать простую рандомизированную структуру данных, называемую skip-список, обеспечивающую логарифмические затраты времени для поиска, аналогичные затратам при использовании бинарного поискового алгоритма. Тем не менее предполагаемые временные затраты при skip-списке будут большими, чем у бинарного поиска в поисковой таблице. С другой стороны, при словарном обновлении skip-список намного быстрее поисковых таблиц.
Пусть skip-список S для словаря D состоит из серии списков {iSo, S\, Si, З/j}. Каждый список S\ хранит набор объектов словаря D по ключам в неубывающей последовательности плюс объекты с двумя специальными ключами, записываемыми в виде «-оо» и «+оо», где «-оо» обозначает меньше, а «+оо» - больше любого возможного ключа, который может быть в D. Кроме того, списки в Sотвечают следующим требованиям:
Список S 0 содержит каждый объект словаря D (плюс специальные объекты с ключами «-оо» и «+оо»);
Для / = 1, …, h – 1 список Si содержит (в дополнение к «-оо» и «+оо») случайно сгенерированный набор объектов из списка S t _ ь
Список S h содержит только «-оо» и «+оо».
Образец такого skip-списка приведен на рис. 8.9, наглядно представляющем списодс S со списком в основании и списками S\, …, S^ над ним. Высоту (height) списка S обозначим как h.
Рис. 8.9. Пример skip-списка
Интуитивно списки организованы таким образом; чтобы?/+/ содержал хотя бы каждый второй объект 5/. Как будет показано при рассмотрении метода ввода, объекты в St+\ выбираются произвольно из объектов в Si с таким расчетом, чтобы каждый выбираемый объект 5/ входил в 5/ + \ с вероятностью 1/2. Образно говоря, помещать или нет объект из в Si + 1, определяем в зависимости от того, какой стороной упадет подкидываемая монетка - орлом или решкой. Таким образом, можно считать, что S\ содержит около я/2 объектов, S2 - я/4, и, соответственно, Sj - около п/2′ объектов. Другими словами, высота h списка S может составлять около logn. Хотя при этом деление пополам числа объектов от одного списка к другому не является обязательным требованием в виде явно выраженного свойства skip-списка. Наоборот, случайный выбор важнее.
Используя позиционную абстракцию применительно к спискам и деревьям, можно рассматривать skip-список как двухмерную коллекцию позиций, организованных горизонтально в уровни (levels) и вертикально в башни (towers). Каждый уровень - это список S^ а каждая башня - набор позиций, хранящих один и тот же объект и расположенных друг над другом в списках. Позиции skip-списка можно проходить с помощью следующих операций:
after(/?): возвращает позицию, следующую за р ца том же уровне; before(/?): возвращает позицию, предшествующую р на том же уровне; below(/?): возвращает позицию, расположенную под р в той же башне; above(/?): возвращает позицию, расположенную над р в той же башне.
Установим, что перечисленные выше операции должны возвращать null, если запрашиваемой позиции не существует. Не вдаваясь в подробности, заметим, что skip-список легко реализуется с помощью связной структуры таким образом, что методы прохода требуют 0(1) времени (при наличии в списке позиции р). Такая связная структура представляет собой коллекцию из h двусвязных списков, объедийёйй^ й^айШ, в свою очередь являющиеся двусвязными списками.
Структура skip-списка позволяет применять простые поисковые алгоритмы для словарей. В действительности все поисковые алгоритмы skip-списка основываются на достаточно элегантном методе SkipSearch, принимающем ключ к и находящим объект в skip-списке S с наибольшим ключом (который может оказаться «-оо»), меньшим или равным к. Допустим, имеется искомый ключ к. Метод SkipSearch устанавливает позицию р в самой верхней левой позиции в skip-списке S. То есть р устанавливается на позиции специального объекта с ключом «-оо» в S^. Затем выполняется следующее:
1) если S.below(/?) равен null, то поиск заканчивается - на уровень ниже обнаружен наибольший объект в Sс ключом, меньшим или равным искомому ключу к. В противном случае опускаемся на один уровень в данной башне, устанавливая р S.be\ow(p);
2) из позиции р продвигаемся вправо (вперед) до тех пор, пока не окажемся в крайней правой позиции текущего уровня, где кеу(/?) < к. Такой шаг называется сканированием вперед (scan forward). Указанная позиция существует всегда, поскольку каждый уровень имеет специальные ключи «+оо» и «-оо». И на самом деле, после шага вправо по текущему уровню р может остаться на исходном месте. В любом случае после этого снова повторяется предыдущее действие.

Рис. 8.10. Пример поиска в skip-списке. Обследованные во время поиска ключа 50 позиции выделены штриховым обозначением
Фрагмент кода 8.4 содержит описание поискового алгоритма skip-списка. Имея такой метод, несложно реализовать операцию findElement(/:). Выполняется операция р^- SkipSearch(A;) и проверяется равенство key{p)~ k. При ^равенстве возвращается /?.element. В противном случае возвращается сигнальное сообщение NO_SUCH_KEY.
Алгоритм SkipSearch(/:):
Input: поисковый кл?оч к.
Output: позиция р в S, объект которой имеет наибольший ключ, меньший или равный к.
Допустим, что р - самая верхняя левая позиция в S (состоящей как минимум из двух уровней), while below (р) * null do
р below(p) {просканировать вниз} while key(after(p)) < к do
Let p after(p) {просканировать вперед} return p
Фрагмент кода 8.4. Алгоритм поиска в skip-списке S
Оказывается, предполагаемое время выполнения алгоритма SkipSearch составляет 0(log п). Прежде чем обосновать это, приведем реализацию методов обновления skip-списка
СКИП – это система контроля исполнения поручений на базе MS SharePoint, позволяющая полностью автоматизировать процесс работы с поручениями. Это продуманное, коробочное решение для организации работы с поручениями. Оно подходит как для работы в крупных и территориально-распределенных компаниях, так и для компаний среднего бизнеса за счет возможности осуществления максимально гибкой настройки всех модулей.
Система СКИП базируется на платформе Microsoft SharePoint, что автоматически означает возможность ее интеграции с продуктами Microsoft, в том числе Microsoft Office.
Функциональные возможности системы
Система СКИП является «коробочным» решением и в этом варианте содержит базовый набор функциональных возможностей, необходимых для автоматизации работы с поручениями:
- Назначение, исполнение, контроль поручения;
- Отслеживание статуса исполнения поручения;
- Возможность создавать вложенные («дочерние») поручения.
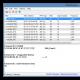
Список поручений с цветовой индикацией
При этом представленный функционал реализован таким образом, чтобы предоставить пользователю максимально широкие возможности по работе с системой:
- Каталогизация поручений (одно поручение может располагаться в различных папках);
- Фильтрация списков поручений;
- Экспорт списков поручений в MS Excel;
- Отчеты по исполнительской дисциплине;
- Цветовая индикация поручений в зависимости от срока исполнения и статуса поручения;
- Возможность прикрепления произвольного количества файлов любых форматов к Карточке поручения;
- Интеграция с календарями Outlook;
- Настраиваемые оповещения о назначении и ходе работы с поручением;
- Система замещения сотрудников на период отпуска или командировки;
- Создание периодических поручений (или поручений с расписанием) для мероприятий, которые имеют определенный период (совещания, встречи и т.д.);
- Отображение сроков исполнения поручений на диаграмме Ганта;
- и прочее
Список поручений с диаграммой Ганта